
The Resistance to Counting, Recounted
Eric Bulson takes it as given that “quantitative readings of literature . . . get a bad rap.” Indeed, the presumed hostility of literary scholars toward quantitative analysis provides the necessary friction for his essay, lending argumentative force and methodological point to what might otherwise seem a rather narrowly focused piece. And it is to highlight the wider stakes involved in Bulson’s contrarian decision to count rather than simply read the words of Ulysses that the editors have invited this accompanying cluster of responses and reflections.
I’m in no position to challenge the view of literary studies as a bastion of numerophobia. I wrote a few years ago that a “negative relation to numbers” is “foundational” to literary studies, which occupies a structural position in the university as the quintessential non-counting discipline. But what strikes me now is that neither Bulson nor I, nor anyone else hoping to expand the space for quantitative analysis in literary research, has presented any quantitative evidence to support this picture of literary scholars as the determined enemies of counting. Wouldn’t “quantitative data… actually help us” in this respect, too, enabling us to take the measure of our presumed hyper-commitment to the qualitative, to calculate its degree and scale relative to other disciplines and to other moments in our own history?
How might such data be gathered? Andrew Goldstone and Ted Underwood have laid down one possible pathway in their “Quiet Transformations of Literary Studies: What Thirteen Thousand Scholars Could Tell Us.”[1] Analyzing a corpus of some 21,000 articles published over the last 120 years in seven major generalist journals of literary study, they counted not just the number of words but the number of “number words” (“from two to hundred and first to tenth”), calculating these as a percentage of all words in the corpus for each year. What they found, surprisingly, was that there used to be a lot more counting going on in our research than there is today: about 50% to 80% more if we compare the first half of the 20th century to the last couple of decades. In fact, based on this particular analysis of this particular dataset, it appears that we have never been so disinclined to quantify as we are at present. It is as if the society’s dominant tendency toward ever more ubiquitous computation and digitization has prompted literary scholars to mount a desperate rear guard action.
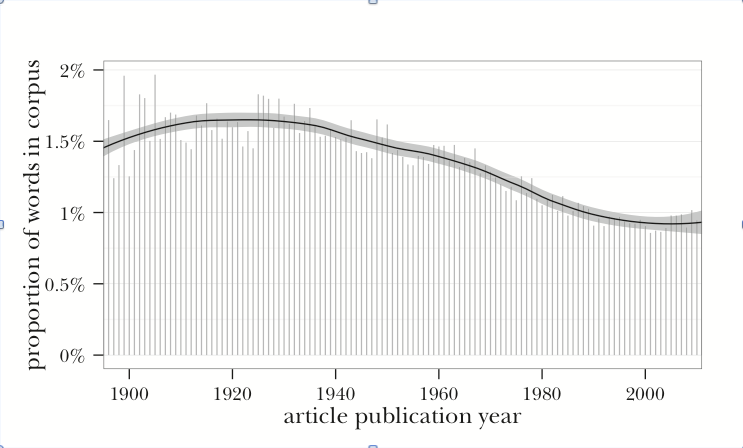
Proportion of “number words” by year in a corpus of articles from seven leading journals of literary study. (Source: Andrew Goldstone and Ted Underwood, “The Quiet Transformations of Literary Studies: What Thirteen Thousand Scholars Could Tell Us,” NLH 45.3 (2014): Fig. 1, p. 362.)
So it would seem, based on this particular analysis of this particular dataset. That of course is the rub. To Goldstone and Underwood, the declining frequency of number words suggests that our antagonism to quantitative modes of cultural study may be less foundational than we imagine: a “relatively recent” development (360). That could be right. But it might rather be the case that even our initially “high” level of about 100 number words per article a century ago placed us emphatically at the low end of the disciplinary spectrum as it then stood. And depending on what’s happened since then in other disciplines, our relative position may actually be more centrist now than it used to be, more proximate to some of the social and cultural sciences. Or if that seems too farfetched, what about our position relative to other humanities disciplines? Perhaps in that softer company our current average of about 60 number words per published article represents an unusually open disposition toward counting, a degree of interest in numbers that, however modest, exceeds that of neighboring fields. Because the dataset provides no basis for comparison with published scholarship besides our own, it cannot be used to support or refute any of these hypotheses about our stance in the larger system of social, cultural, and historical research.
To pursue these matters at all rigorously, then, we would need an expanded dataset that includes long runs of more or less comparable generalist journals from a representative range of disciplines. This in itself would present non-trivial challenges, and would require at the very least our consultation with experts from other academic domains to help us pin down the discipline-specific meanings of “generalist” and the relevant hierarchies of journals. But we would then also need to extract from the expanded dataset some different kinds of numbers about the use of numbers. It’s likely that we would have to look beyond “number words” alone for a reliable proxy of quantitative orientations across the disciplines, including for example mathematical terms such as mean, median, percentile, quartile, ratio, variable—maybe the word number itself. And then we would want to know not just the yearly frequencies of these words but how evenly or unevenly dispersed they are across the articles of a given discipline. Does the vocabulary of counting tend to cluster heavily in a subset of articles, which we might then interpret as representing a discipline’s “quantitative wing”? This information would help us to see not just whether literary studies is (as we presume) more dominated than other disciplines by qualitative scholarship, but whether it nonetheless harbors a statistically discernible zone or subfield in which counting is normal practice. The evolving historical position of that subfield within our discipline might then be compared to corresponding trends across the disciplines, be they toward more militant methodological divisions (with increasingly tight concentration of number words in more distinct subsets of articles) or rather toward increasing accommodation of mixed methods (with number words scattering more evenly across each disciplinary corpus). Other historical trends might be brought into the analysis, as well, probing correlations between, for example, declining frequencies of number words and declining percentages of male faculty.
By this stage in our expanding program of research, we would, I hope, begin to question our procedure of treating all the articles in the corpus as though they are equally representative of a discipline’s general practices and preoccupations. We know there are journal articles that practically everyone in the profession has read, and others, even in “major,” “leading,” or “generalist” journals, that practically no one has. Why, if we are serious about gathering and analyzing numbers, would we be satisfied to count every article (or every word of every article) as 1 instead of assigning them weights based on the extent (however approximated) of their circulation or subsequent citation? This indeed has been a failing of most of the work in literary studies that deals with large digitized corpora. Franco Moretti was right to insist that the data appropriate to the study of literary history exceeds the small canon of classics and includes a vast “slaughterhouse” of forgotten works. But that does not mean we can gain much purchase on literary history by treating every book in the slaughterhouse as equivalent, whether it sold in the millions initially but didn’t last, endured as a kind of coterie favorite, or failed ever to find any readers at all. Working with data on a larger scale does not relieve us of the burden of valuation any more than it does that of interpretation. On the contrary, scale and value present themselves as the entwined problems of all quantitative research. As soon as you settle on a scale for your data and metadata, determining to include some things in your counting but not others (authors but not author genders; journals but not books; journal articles but not journal circulation figures; articles in Modern Language Review but not in Modern Language Notes; number words but not mathematical concept words, etc.), you have assumed a whole set of value propositions, most of them highly contestable and capable of exerting a significant effect on your conclusions.
Goldstone and Underwood are well aware of these challenges, careful to specify the assumptions built into their dataset and the uncertainties involved in its interpretation. Their aim in constructing topic models of literary research is not to produce by this means a new history of our discipline but merely to sketch a few provisional contours of that history as a provocation to further inquiry. Likewise Bulson, whose data are strictly limited to the “264,448 graphic units (or language tokens)” of Ulysses and whose claims do not at this stage venture beyond that one supremely canonical novel. He leaves open the question whether Joyce’s relationship to the serial format is generalizable to other authors, whether this particular story, wherein the rigorous constraints of publishing lead unexpectedly to radical freedoms of language and style, might be scaled up to yield a larger historical narrative about modernism’s debts to seriality.
Is Bulson’s ongoing work on this question—with all the sifting and counting it will involve (his data “expanded to include more novels and little magazines,” more authors, more varieties of modernism)—part of a quantitative turn, what Goldstone and Underwood describe as “a recent tendency for literary studies to develop stronger connections to social science” (379)? This is another question that must be left open for further and better-designed forms of inquiry. We have a way to go yet before we can even discern such relational tendencies with confidence, let alone gauge their significance in the history of disciplinary practices.
James F. English
University of Pennsylvania
[1] Andrew Goldstone and Ted Underwood, “The Quiet Transformation of Literary Studies: What Thirteen Thousand Scholars Could Tell Us,” New Literary History 45.3 (Summer 2014): 359. Just as engrossing as this article is the Quiet Transformations website (http://www.rci.rutgers.edu/ag978/quiet), which offers user-friendly tools for further exploration of the dataset.